
SVC (Singing Voice Conversions) is a deep learning model that is aimed at converting a singing voice into another voice keeping the lyrics and music of the song intact.
SVC works on the same principles and technology as AI voice changer but instead of speech, singing voice is converted.
If you are wondering how to use the SVC voice changer then read on. This article will discuss the tutorial of SVC voice changer.
What is SVC Voice Changer?
SVC voice changer is mostly a conversion of a singing voice to another voice with the same music. This model is very different from the VITS model based on text-to-speech conversions.
The VITS model is not capable of performing SVC tasks. The SVC model utilizes a SoftVC content encoder to convert the speech part from the main audio.
The extracted speech is then made to go through VITS without needing text-based representation. Thus the original audio’s music and pitch are not disturbed.
For any SVC conversions, you can use so-vits-svc, available on GitHub for download or a more enhanced user interface version called so-vits-svc-fork.
How To Use SVC Voice Changer?
So-vits-vc-fork is open-source software available on GitHub for anyone to use to train their AI models for voice conversions in any language.
The improvised version supports real-time voice conversions and has a very easy installation process. You can use it with any graphic card with Linux or Microsoft Windows.
To use the SVC voice changer following are the steps for so-vits-vc-fork which has a more improved user interface.
1. For Installation
You can install so-vits-vc-fork either from pip or GitHub.
To install using pip, run the following command:
python -m pip install -U pip setuptools wheel
pip install -U torch torchaudio –index-url https://download.pytorch.org/whl/cu118
pip install -U so-vits-svc-fork
To install using GitHub, run the following command which will clone the repository to install it manually.
git clone https://github.com/voicepaw/so-vits-svc-fork.git
cd so-vits-svc-fork
pip install -e.
For new features and bug fixes keep updating “pip install -U so-vits-svc-fork” on pip and for GitHub, run the following command:
cd so-vits-svc-fork
git pull
pip install -e.
2. Use The Software
It is very easy to use so-vits-vc-fork and to do the voice conversions you can use either GUI or CLI.
Using GUI you can run the following command to open a window.
svc gui
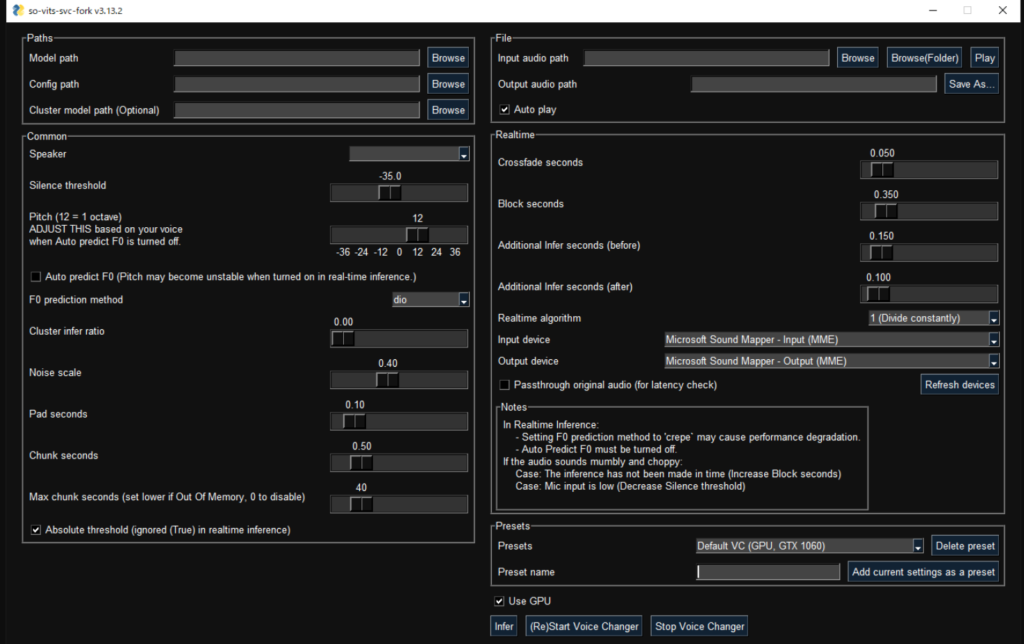
When the window opens, you will see buttons and sliders to control the voice conversions and it also allows you to do the following:
- Load your source speaker from a file or use pre-trained speakers.
- Load your target speaker from a file or use pre-trained target speakers.
- Change the pitch of the converted voice using pitch shift.
- Alter the loudness of the converted voice using the energy ratio.
- Alter the speed of the converted voice using the duration ratio factor.
- Use the play button to hear the converted voice.
- Use the convert button to convert from the source voice to the target voice.
- Use the stop button to stop the conversion playback.
- Use the save button to save the final audio as a WAV file.
The GUI is an entertaining way to convert voices and you can also use your voice to convert it to another person’s singing voice. You can play with different control settings to create a unique voice with various effects.
Using CLI, run the following command which will let you do the voice change using arguments and options.
svc convert [OPTIONS] SOURCE_VOICE TARGET_SPEAKER
The command will help you to convert the source speaker to the target speaker and finally save it as a WAV file.
To open the help in CLI for various inputs and options use -h or – -help.
The CLI option can be technical and used to perform batch conversions of voice by giving commands.
However, if you are new to the SVC, you can use the GUI which is a more user-friendly option to convert the voice without much technical assistance.
SVC Voice Changer Models
There is a huge list of pre-trained models that you can use for voice conversion in the so-vits-vc-fork software.
You can download the models from Hugging Face or CIVITAI.
Notes For Using So-vits-vc-fork Software
When using WSL (Windows Subsystems for Linux), remember that it requires additional set-up of the audio device and the GUI will not work properly without an audio device.
If you find any noise in the real-time inference then HuBert will react to it. It is better to use real-time noise reduction applications such as RTX Voice from Nvidia.
When downloading the pre-trained models ensure that the models are other than 4.0v1 as they are not supported.
Ensure you have a GPU interface with 4GB of VRAM and if not then try CPU inference.